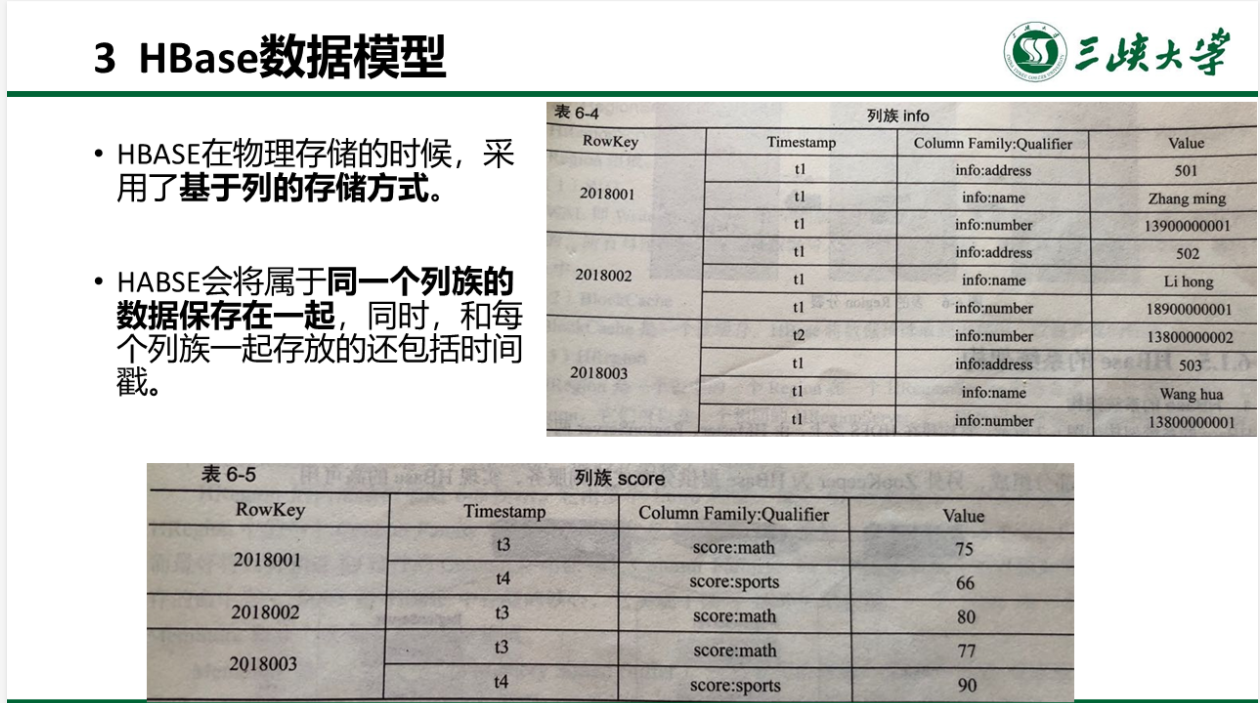
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
| 任务描述
相关知识
任务描述
本关任务:使用python代码向HBase表中并添加、删除数据,并查看数据。
相关知识
一、添加数据
要对一个表添加数据,我们需要一个table对象,使用table.put()方法添加数据:
在上一关的例子中,我们创建了my_table表包含3个列族:cf1、cf2、cf3,现在我们往里面写入数据。你可以试试先自己创建这个my_table表。
table = connection.table(‘my_table’)
Hbase里 存储的数据都是原始的字节字符串
cloth_data = {'cf1:content': 'jeans', 'cf1:price': '299', 'cf1:rating': '98%'}
hat_data = {'cf1:content': 'cap', 'cf1:price': '88', 'cf1:rating': '99%'}
shoe_data = {'cf1:content': 'jacket', 'cf1:price': '988', 'cf1:rating': '100%'}
author_data = {'cf2:name': 'LiuLin', 'cf2:date': '2017-03-09'}
table.put(row='www.test1.com', data=cloth_data)
table.put(row='www.test2.com', data=hat_data)
table.put(row='www.test3.com', data=shoe_data)
table.put(row='www.test4.com', data=author_data)
使用put一次只能存储一行数据
如果row key已经存在,则变成了修改数据
更好的存储数据
table.put()方法会立即给Hbase Thrift server发送一条命令。其实这种方法的效率并不高,我们可以使用更高效的table.batch()方法。
使用batch一次插入多行数据
bat = table.batch()
bat.put('www.test5.com', {'cf1:price': 999, 'cf2:title': 'Hello Python', 'cf2:length': 34, 'cf3:code': 'A43'})
bat.put('www.test6.com', {'cf1:content': 'razor', 'cf1:price': 168, 'cf1:rating': '97%'})
bat.put('www.test7.com', {'cf3:function': 'print'})
bat.send()
更有用的方法是使用上下文管理器来管理batch,这样就不用手动发送数据了,即不再需要bat.send()
*使用with来管理batch *
with table.batch() as bat:
bat.put('www.test5.com', {'cf1:price': '999', 'cf2:title': 'Hello Python', 'cf2:length': '34', 'cf3:code': 'A43'})
bat.put('www.test6.com', {'cf1:content': u'剃须刀', 'cf1:price': '168', 'cf1:rating': '97%'})
bat.put('www.test7.com', {'cf3:function': 'print'})
二、删除数据
在batch中删除数据with table.batch() as bat:
bat.delete(‘www.test1.com')
batch将数据保存在内存中,知道数据被send,第一种send数据的方法是显示地发送,即bat.send(),第二种send数据的方法是到达with上下文管理器的结尾自动发送。
** 三、检索数据**
全局扫描一个table
for key, value in table.scan():
print key, value
结果如下:
,
检索一行数据
row = table.row(‘www.test4.com') print row
直接返回该row key的值(以字典的形式),结果为:
{‘cf2:name’: ‘LiuLin’, ‘cf2:date’: ‘2017-03-09’}
检索多行数据
rows = table.rows([‘www.test1.com', ‘www.test4.com'])print rows
返回的是一个list,list的一个元素是一个tuple,tuple的第一个元素是rowkey,第二个元素是rowkey的值
如果想使检索多行数据即table.rows()返回的结果是一个字典,可以这样处理检索多行数据,返回字典
rows_dict = dict(table.rows([‘www.test1.com', ‘www.test4.com']))print rows_dict
如果想使table.rows()返回的结果是一个有序字典,即OrderedDict,可以这样处理检索多行数据,返回有序字典
from collection import OrderedDict
rows_ordered_dict = OrderedDict(table.rows([‘www.test1.com', ‘www.test4.com']))
print rows_ordered_dict
好了,下面开始你的任务啦:
按照右边的文件要求补完代码。
预期输出:
OrderedDict([(b’info:name’, b’John’), (b’scores:Bigdata’, b’89’), (b’scores:database’, b’88’)])
b’95001’ OrderedDict([(b’info:name’, b’John’), (b’scores:Bigdata’, b’89’), (b’scores:database’, b’88’)])
b’95002’ OrderedDict([(b’info:name’, b’Rose’), (b’scores:database’, b’68’)])
b’95003’ OrderedDict([(b’info:name’, b’Greens’), (b’scores:Bigdata’, b’76’)])
如果运行结果报错提示显示表已经存在,
,
查看各个服务进程是否启动
‘’
root@evassh-2932225:~
1808 ResourceManager
4785 Jps
2820 ThriftServer
1317 NameNode
2694 HRegionServer
1447 DataNode
2506 HQuorumPeer
1626 SecondaryNameNode
2570 HMaster
‘’
如果处于启动状态就到到hbase shell中手动删除该表。
开始你的任务吧,祝你成功!
|